




Im Juli 2025 nahm OpenAI an der Internationalen Mathematikolympiade teil – und gewann Gold. Sie taten dies nicht, indem sie vergangene Probleme auswendig lernten, sondern indem sie Schritt für Schritt wie menschliche Wettkämpfer argumentierten.
Einen Monat später trat OpenAI beim analogen Programmierwettbewerb, der Internationalen Olympiade in Informatik (IOI) an – und sicherte sich erneut Gold. Und sie gewannen mit dem gleichen Modell. Alexander Wei, Head of Reasoning bei OpenAI, fasste den Durchbruch in zwei Worten zusammen: "Reasoning verallgemeinert!"
Künstliche Intelligenz erlebt einen fundamentalen Paradigmenwechsel. In den letzten zehn Jahren haben sich KI-Systeme von analytischer KI (Modelle, die strukturierte Daten mit deterministischen Ausgaben analysieren) zu generativer KI (Deep-Learning-Modelle, die in der Lage sind, unstrukturierte Ausgaben wie Text und Bilder zu erzeugen) entwickelt. Jetzt erleben wir das Aufkommen einer neuen Grenze: Reasoning AI, zielstrebige Agenten, die iterativ denken, ihre eigenen Fehler korrigieren und langfristige Aufgaben bewältigen können.
Diese nächste Generation kombiniert selbstüberwachte Grundlagenmodelle mit Reinforcement Learning (RL) und massiven Testzeitberechnungen und ermöglicht es der KI, über die Mustererkennung hinaus zu echter Inferenz und Anpassung überzugehen. Diese Systeme gehen überdie Vorhersage des nächsten Schrittshinaus und planen aktiv mehrere Schritte im Voraus und passen ihren Ansatz kontinuierlich an, um ein definiertes Ziel zu erreichen .
Wir sehen den Aufstieg von Reasoning AI als eigenständige Fähigkeitsstufe als einen wichtigen Wendepunkt auf dem Markt. Jobs und Aufgaben, die bisher als "nicht automatisierbar" oder "außerhalb des Rahmens dessen, was KI leisten kann", galten, sind nun in Reichweite. Denken Sie an einen schwer zu diagnostizierenden medizinischen Fall oder die Erstellung einer komplexen Steuererklärung; Wir können jetzt eine nahe Zukunft sehen, in der Aufgaben, die in den Trainingsdaten nicht gut dargestellt werden oder sogar völlig neu sind , von Reasoning AI erledigt werden können. Konventionelle Weisheiten wie "Es wird immer einen Teil dieser Arbeit geben, der nur von einem Menschen erledigt werden kann" müssen überdacht werden. Reasoning AI hat Auswirkungen darauf, wie man sich der Entscheidung "menschliche Unterstützung vs. Vollautomatisierung" beim Produktdesign nähert, und sie eröffnet Gründern neue Marktchancen.
Dieser Essay untersucht die Mechanismen hinter dieser Verschiebung, präsentiert empirische Beweise aus neuen Benchmarks, untersucht die Auswirkungen auf die reale Welt anhand detaillierter Fallstudien und diskutiert, wie die neue Generation von Reasoning AI-Unternehmen weit davon entfernt sein wird, "LLM-Wrapper" zu sein.
Argumentation KI: Eine neue Grenze der Fähigkeiten
So wie der Wechsel von traditioneller Software zu maschinellem Lernen die analytische KI einführte und die Entwicklung tiefer neuronaler Netze auf unstrukturierten Daten zu generativer KI führte, markiert der Aufstieg der Reasoning AI eine neue Grenze der Fähigkeiten. Mit jeder Ära wurde der Umfang der Aufgaben erweitert, die Maschinen bewältigen können:
Analytische KI (vor 2015): Diese Systeme konzentrierten sich auf strukturierte Daten und statische Vorhersagen. Denken Sie an Regressionsmodelle oder Entscheidungsbäume in Datenbanken. Sie zeichneten sich durch enge, klar definierte Aufgaben wie Kreditbewertung, Lieferkettenoptimierung oder Anomalieerkennung aus. Analytische KI erwies sich in eingeschränkten Bereichen als leistungsfähig, blieb aber grundsätzlich auf die Zuordnung von Eingaben zu Ausgaben auf der Grundlage von Mustern in historischen strukturierten Daten beschränkt. Es fehlte an Kreativität und konnte nicht weit über seine Trainingsverteilung hinaus verallgemeinert werden.
Generative KI (2016-2023): Diese Ära, die durch groß angelegtes Deep Learning katalysiert wurde, brachte Modelle hervor, die unstrukturierte Daten (Text, Bilder, Audio) aufnehmen und neue Inhalte generieren. Systeme wie GPT-3 und DALL· E wurden durch selbstüberwachtes Lernen an Korpora im Internetmaßstab trainiert, was sie in die Lage versetzte, Texte und Bilder mit bemerkenswerter Gewandtheit zu synthetisieren. Generative KI zeigte beeindruckende Kreativität und einen ergebnisoffenen Output, aber diese Modelle bleiben im Grunde genommen Musternachahmer: Sie prognostizieren wahrscheinliche Fortsetzungen oder Fertigstellungen auf der Grundlage von Trainingsdaten. Ihnen fehlt eine explizite Vorstellung von Zielen oder eine mehrstufige Planung. Ein generatives Sprachmodell kann in einem Durchgang einen plausibel klingenden Aufsatz oder Codeschnipsel erzeugen, aber es wird keine Lösungsstrategie planen oder Fehler selbst korrigieren, es sei denn, es wird explizit dazu aufgefordert.
KI des logischen Denkens (2024+): Das entstehende Paradigma baut auf generativen Modellen auf, fügt aber Deliberation und zielgerichtetes Denken hinzu. Logisch denkende KI-Systeme nutzen die Grundlage großer selbstüberwachter Modelle (die ein breites Wissen und Mustererkennung bieten), stimmen sie dann mit Reinforcement Learning für bestimmte Ziele ab und ermöglichen vor allem iterative Berechnungen zur Inferenzzeit. Anstelle einer einmaligen Vorhersage führt das Modell einen mehrstufigen Denkprozess durch: Es werden Zwischenschritte generiert, die Ergebnisse überprüft und der Ansatz verfeinert. Diese Integration von langfristiger Planung und Feedback bedeutet, dass Reasoning AI Probleme angehen kann, die eine Abfolge von logischen Schlussfolgerungen oder Aktionen erfordern, bei denen die einfache Nachahmung von Trainingsdaten zu kurz greifen würde. Ein Reasoning AI-Agent, der mit einer neuartigen Aufgabe konfrontiert wird, kann intern einen Denkprozess simulieren, verschiedene Lösungswege erkunden und bei Bedarf zurückverfolgen, ähnlich wie es ein menschlicher Denker tun würde.
Diese Verschiebung zu Reasoning AI ist eine grundlegende Veränderung der Fähigkeiten. RL-trainierte Argumentationsmodelle übertreffen generative Standardmodelle erheblich. Große Sprachmodelle, die nur über selbstüberwachtes Lernen (SSL) optimiert werden, haben ein Plateau bei Aufgaben wie komplexer Mathematik oder Codesynthese. Das Hinzufügen einer Ebene mit universellem RL-Training hebt die Leistung auf ein neues Niveau. Top-Forschungslabore haben sich auf das Training von Allzweck-Denkmodellen im Gegensatz zum Training aufgabenspezifischer Modelle konzentriert. Diese Agenten sind nicht dafür gemacht, ein einzelnes Spiel zu spielen oder einfachen Anweisungen zu folgen, sondern um komplexe mathematische Probleme zu lösen, korrekten Code zu schreiben, formale Beweise abzuleiten, einen Computer zu bedienen und vieles mehr, was zu bemerkenswerten Erfolgen führt. Wenn es bei der generativen KI um unstrukturierte Synthese ging, geht es bei der Reasoning AI um strukturierte Problemlösung. Es versucht, Ziele in einem offenen Umfeld zu erreichen, indem es Pläne entwickelt und umsetzt, anstatt einmalige Antworten zu produzieren.
Die Implikationen sind tiefgreifend. Analytische KI automatisiert weitgehend die Zahlenverarbeitung und Vorhersage auf der Grundlage sauberer Daten. Generative KI automatisierte die Erstellung von Inhalten und stellte fließende Schnittstellen wie Konversationsassistenten und Bildgenerierung bereit. Reasoning AI hat das Potenzial, kognitive Arbeitsabläufe zu automatisieren – die mehrstufigen, entscheidungsgeladenen Aufgaben, die bisher nur Experten ausführen konnten. Dazu gehören Bereiche, die "hochkomplex, schwer zu überprüfen" sind und in denen Erfolg nicht nur darin besteht, etwas zu produzieren, das richtig aussieht, sondern auch darin, einen langwierigen Prozess zu durchlaufen, der in vielen Phasen leicht schief gehen kann. Denken Sie an das Debuggen komplexer Software, die Diagnose einer Krankheit anhand von Symptomen, das Erstellen und Verhandeln von Rechtsverträgen oder die Erstellung von Unternehmenssteuererklärungen. Diese Prozesse umfassen die Planung, das Reagieren auf neue Informationen und die kontinuierliche Fehlerprüfung. Bisher wurden solche Workflows weit über den Rahmen von KI hinaus betrachtet. Mit Reasoning AI ändert sich das schnell.
Zwei Hebel, die alles veränderten: RL + Test-Time-Compute
Im Mittelpunkt von Reasoning AI steht das Konzept, dass ein KI-Modell nachdenken kann. Anstatt in einem Schritt direkt von der Eingabe auf die Ausgabe abzubilden, führt ein Reasoning Agent eine Abfolge von internen Operationen durch – Denkschritte, die allgemein als Chain-of-Thought (CoT) bezeichnet werden – bevor er ein Ergebnis liefert. Diese Fähigkeit ergibt sich aus zwei wichtigen Innovationen: Sie ermöglicht deutlich mehr Rechenleistung zum Zeitpunkt der Inferenz und trainiert das Modell mit Reinforcement Learning, damit es nützliche interne Strategien (wie Planung, Speichernutzung und Fehlerkorrektur) entwickelt, die Menschen normalerweise zur Entwicklung von Lösungen verwenden.
Iteratives Denken über Test-Time-Compute
Traditionell eingesetzte KI-Modelle wurden bei der Inferenz "fixiert"; Sie leiten Eingaben einmal durch das neuronale Netz und geben eine Antwort aus. Wenn die Antwort falsch ist, gibt es keine zweite Chance, es sei denn, Sie trainieren das Modell neu oder fordern es erneut von Grund auf auf. Test-Time-Computing ändert dieses Paradigma, indem es den Modellen Raum zum "Denken" gibt. In der Praxis bedeutet dies, das Modell für mehrere Vorwärtsdurchläufe auszuführen, Zwischen-CoTs zu generieren, viele mögliche Antworten parallel zu untersuchen oder auf andere Weise mehr Berechnungen pro Abfrage als bei einem standardmäßigen Einzeldurchlauf zu verwenden. Wir können zusätzliche Rechenleistung gegen eine bessere Genauigkeit im laufenden Betrieb eintauschen.
In den heutigen Systemen gibt es mehrere Formen dieser "Denkzeit". Die CoT-Eingabeaufforderung fordert das Modell auf, eine Schritt-für-Schritt-Argumentationsspur zu erstellen, bevor es zu einer Schlussfolgerung kommt. Mehrheitsentscheidungen oder Best-of-N-Stichproben generieren viele mögliche Antworten und wählen die häufigste oder am höchsten bewertete Antwort aus. Ausgefeiltere Ansätze wie Tree-of-Thoughts ermöglichen es dem Modell, mehrere Argumentationspfade zu verzweigen, Teillösungen zu bewerten und entweder zurückzugehen oder vielversprechende Wege zu verfolgen. All diesen Techniken gemein ist das Prinzip der iterativen Verfeinerung.
Empirisch hat sich die Berechnung von Testzeitpunkten als äußerst leistungsfähig erwiesen. OpenAI-Forscher stellen fest, dass sich ihre neuen Modelle deutlich verbessern, wenn mehr Zeit mit dem Nachdenken verbracht wird (Test-Time-Computing), auch ohne die Gewichtung des Modells zu ändern. Bei der Bewältigung komplexer Codierungsprobleme versuchen moderne Denkmodelle nicht nur eine Lösung. Siegenerieren Dutzende von Kandidatenprogrammen, testen sie anhand von Unit-Fällen und verfeinern sie.
Eine dramatische Fallstudie ist das o3-Ergebnis von OpenAI im ARC-Benchmark (Abstraction and Reasoning Corpus). ARC wurde als allgemeiner Intelligenztest konzipiert, der für den Menschen einfach und für die KI extrem schwer ist, bei dem die reine Mustererkennung versagt. Frühere generative Modelle erzielten einen Wert von nahezu 0 %. Das "o3"-Modell von OpenAI erzielte einen Durchbruch: Unter einem Standard-Rechenbudget erzielte es etwa 75 % in der ARC-Bewertung – und wenn es mit einer um 172 × höheren Rechenleistung ausgeführt wurde (Tausende von parallelen Lösungen, die innerhalb von 10 Minuten untersucht wurden) – erreichte es 87,5 % und übertraf damit die Schwelle auf menschlicher Ebene. Das Ergebnis war eine "Steigerung der Stufenfunktion" der Fähigkeiten, die "eine neuartige Fähigkeit zur Aufgabenanpassung offenbarte, die noch nie zuvor in den Modellen der GPT-Familie gesehen wurde". Durch die Investition von mehr Denkzeit in das Problem erreichte die KI ein qualitativ höheres Niveau der Problemlösung. Die ARC-Ergebnisse zeigten, dass "die Leistung bei neuartigen Aufgaben mit zunehmender Rechenleistung verbessert wird", aber dass dies nicht nur Brute-Force war; Es erforderte die neue Modellarchitektur. Dies unterstreicht, wie die iterative Inferenz eine neue Verbesserungsachse eröffnet hat, orthogonal zur reinen Skalierung der Modellgröße oder der Datensatzgröße. François Chollet, der den ARC-Test entwickelt hat, schrieb, dass "die gesamte Intuition über KI-Fähigkeiten für o3 aktualisiert werden muss".
Forscher erforschen Möglichkeiten, wie KI-Modelle während der Inferenz lernen und sich verbessern können, nicht nur während des Offline-Trainings. Test-Time Reinforcement Learning (TTRL), das von Zuo et al. eingeführt wurde, ist eine solche Methode. Es behandelt jede neue Frage als eine Mini-Lernumgebung, in der das Modell mehrere Antworten generiert und die Übereinstimmung zwischen ihnen als Signal dafür verwendet, was wahrscheinlich richtig ist. Wenn die meisten Antworten übereinstimmen, wird dieser Konsens als Belohnung gewertet, so dass das Modell die Muster verstärken kann, die zu ihm geführt haben. Überraschenderweise ermöglicht dieser Ansatz eine Verbesserung des Modells über seine ursprünglichen Fähigkeiten hinaus, auch ohne beschriftete Trainingsdaten. In einigen Fällen schneidet die Gültigkeitsstrg fast genauso gut ab wie Modelle, die direkt auf dem Testsatz mit echten Antworten trainiert wurden. Obwohl sich TTRL noch in einem frühen Forschungsstadium befindet, weist es auf KI-Systeme hin, die sich in Echtzeit anpassen und weiterentwickeln können, indem sie einfach mit neuen Problemen interagieren.
Die Berechnung zur Testzeit verleiht der KI aktive Problemlösungskapazitäten. Anstatt auf einen Vorwärtsdurchgang beschränkt zu sein, können Modelle jetzt Denkprozesse beliebiger Länge simulieren, die nur durch verfügbare Rechenleistung begrenzt sind. Dies ermöglicht langfristiges Denken: Das Modell kann Aufgaben bewältigen, die Dutzende von Zwischenberechnungen oder Entscheidungen erfordern, indem es Rechenleistung zuweist, um sie schrittweise zu durchlaufen. Die "statischen" generativen Modelle der letzten Jahre antworteten sofort, aber manchmal impulsiv und falsch. Der neue Ansatz ähnelt einem fleißigen Denker, der sich Zeit nimmt, über Dinge nachdenkt, doppelt prüft und bei Bedarf von vorne anfangen kann.
Zielorientierte Optimierung mit Reinforced Learning
Größere Denkzeit würde verschwendet, wenn die Modelle nicht wüssten, wie sie sie produktiv einsetzen können. Reinforcement Learning geht hier an, indem es KI-Systeme mit expliziten Belohnungssignalen für das Erreichen von Zielen trainiert und sie mit Intentionalität durchtränkt – einem Antrieb, Dinge richtig herauszufinden, anstatt nur plausible Ergebnisse nachzuahmen. Reinforcement Learning verwandelt ein passives Vorhersagemodell in einen aktiven Agenten, der versucht, etwas zu erreichen. "The Paradigm" von James Betker von der OpenAI-Forschung ist eine großartige Einführung in dieses Thema.
Wenn wir ein Modell mit RL optimieren, bitten wir es nicht mehr, die Wahrscheinlichkeitsverteilung eines Datasets zu modellieren. Stattdessen definieren wir eine Belohnungsfunktion für gewünschtes Verhalten und lassen das Modell Sequenzen von Aktionen (oder Token-Generierungen) untersuchen, die eine hohe Belohnung liefern. Jede Sequenz von Modellgedanken und -ausgaben kann als eine Flugbahn durch eine Umgebung gesehen werden. Der RL-Trainingsprozess passt das Modell so an, dass Trajektorien mit guter Punktzahl erzeugt werden. Das Modell lernt eine Richtlinie: eine Zuordnung von Zuständen (dem aktuellen Kontext oder einer Teillösung) zu den nächsten Aktionen (dem nächsten Token oder der nächsten Entscheidung), die tendenziell zum Erreichen des Ziels führen.
Ein unmittelbarer Effekt: Das Modell entwickelt nützliche Subroutinen – verinnerlichte Strategien, um wiederkehrende Situationen beim Lösen von Aufgaben zu bewältigen. So wie Menschen unbewusst Fähigkeiten erlernen, die kombiniert werden können (Autofahren beinhaltet Unterprogramme wie Schalten, Spiegel überprüfen, Pedale drücken), kann ein großes Sprachmodell Subroutinen lernen, um von "Das ist ein schwieriges Problem und ich sollte härter nachdenken" auf gängige Programmiermuster zu schließen. Diese Kompetenzen entstehen, weil sie dazu beitragen, Belohnung zu erzielen. RL-trainierte Denkmodelle weisen charakteristische Verhaltensweisen wie Scratchpad-Berechnungen, logische Schritt-für-Schritt-Schlussfolgerungen und selbstüberprüfende Phrasen auf. Sie erwerben modulare Fähigkeiten, die miteinander verkettet werden können, um Ziele zu erreichen.
Die vielleicht wirkungsvollste neue Fähigkeit ist die Fehlerkorrektur. Standardsprachmodelle, die rein über Wahrscheinlichkeitslernen trainiert werden, haben keinen Mechanismus, um sich wirklich zu korrigieren, wenn sie vom Weg abkommen. Ihnen wurde nie explizit beigebracht, was zu tun ist, wenn Fehler passieren. Wenn ein generatives Modell eine unplausible Tokensequenz erzeugt, verfügt es über keinen integrierten Antrieb, um wieder auf Kurs zu kommen. RL ändert das. Indem nur erfolgreiche Endergebnisse (und vielleicht einige Zwischenmeilensteine) belohnt werden, lernt das Modell, zu erkennen, wann es vom Weg abkommt, und Korrekturmaßnahmen zu ergreifen. Mit RL trainierte Allzweck-Denkmodelle zeigen oft ein Zweifelsverhalten und verwenden Wörter wie "aber", "außer" oder "vielleicht", wenn sie potenzielle Fehler erkennen und ihren Ansatz überarbeiten. Diese Selbstkorrektur fehlte in reinen vortrainierten Modellen im Wesentlichen. Sie entsteht, weil das RL-Ziel explizit Anreize für korrekte Ergebnisse bietet und das Modell dazu zwingt, interne Checks and Balances zu entwickeln. Das standardmäßige wahrscheinlichkeitsbasierte Training ermöglicht es Modellen, intelligente Verhaltensmuster zu replizieren, bereitet sie jedoch nicht auf neuartige oder unerwartete Szenarien vor. Im Gegensatz dazu entwickeln Modelle, die mit allgemeiner RL trainiert wurden, von Anfang an Fehlerkorrekturfähigkeiten. Ein auf RL abgestimmtes Modell lernt, was zu tun ist, wenn es es nicht weiß, und es kann einen anderen Ansatz ausprobieren oder vorherige Schritte sorgfältig neu bewerten. Die neuesten Modelle erkennen, wenn sie falsch liegen , und halluzinieren nicht nur eine Best-Guess: Die IMO-KI von OpenAI scheint hier erhebliche Fortschritte gemacht zu haben.
RL macht Modelle damit zielstrebig und robust. Anstatt Trainingsdaten passiv wiederzukäuen, versucht das Modell aktiv, die Belohnung zu maximieren, was in der Regel bedeutet, das vorliegende Problem zu lösen. Beim Programmieren kann die Belohnung darin bestehen, alle Komponententests zu bestehen. in Mathematik, die richtige numerische Antwort zu erhalten; im Dialog, um den Benutzer zufrieden zu stellen oder den Anweisungen zu folgen. Überall dort, wo wir ein klar definiertes Maß für den Erfolg haben, können wir RL verwenden, um das Modell so zu pushen, dass es dafür optimiert wird. Dies hat zu dem geführt, was man als Large Reasoning Models (LRMs) bezeichnen könnte, Sprachmodelle, die darauf abgestimmt sind, mehrstufiges Denken zuverlässig durchzuführen. Solche Modelle folgen längeren Argumentationsketten, verfolgen Fehler zurück und unterteilen Probleme dank RL oder verwandten Techniken in Teilschritte.
Es lohnt sich, ein Missverständnis zu klären: Einige gehen davon aus, dass RL bei Sprachmodellen diese nur geringfügig verfeinert. In der Realität kann ein längeres und generalistisches RL-Training völlig neue Lösungsstrategien erschließen, die im Basismodell nicht vorhanden sind. Das IMO Gold Math-Modell von OpenAI ist das gleiche wie das IOI Gold-Codierungsmodell. OpenAI hat kein Modell speziell für IOI trainiert – "Das Denken verallgemeinert!"
Forscher haben herausgefunden, dass Modelle mit ausreichender RL-Optimierung für verschiedene Denkaufgaben Problemlösungsmethoden entdecken können, die nicht in ihren Erfahrungen vor dem Training enthalten waren. Das ProRL-Papier stellt fest, dass "RL neue Lösungswege entdecken kann, die in Basismodellen völlig fehlen, wenn ausreichend Trainingszeit und neuartige Denkaufgaben zur Verfügung stehen." Interessanterweise zeigten schwächere Basismodelle die stärksten Gewinne durch ProRL, wahrscheinlich weil sie tiefer hängende Früchte hatten und gezwungen waren, neue Denkmuster zu entwickeln, um eine Belohnung zu erhalten. Dies deutet darauf hin, dass RL mehr als nur die Feinabstimmung bekannter Fähigkeiten leistet. Es verschiebt die Grenzen dessen, was Modelle leisten können.
Eine Benchmark-Suite namens Reasoning Gym, die prozedural generierte Logikprobleme mit überprüfbaren Lösungen bereitstellt, zeigte einen Leistungsunterschied von 22 % zwischen dem besten RL-trainierten Modell und dem besten Nicht-RL-Modell – selbst wenn das Nicht-RL-Modell größer war! Kleinere Modelle, die einer argumentationslastigen RL unterzogen worden waren, schnitten besser ab als größere Modelle, die dies nicht getan hatten, und zeigten, dass "RL qualitativ unterschiedliche Fähigkeiten freischaltet" und eher zu breit anwendbaren Problemlösungsfähigkeiten als zu engen Tricks führt.
Diese Entwicklungen weisen auf ein Kernthema hin: Trajektorienoptimierung versus statische Vorhersage. Ein generatives Modell versucht, eine Ausgabe vorherzusagen, aber ein Reasoning Agent versucht, ein Ergebnis zu erzielen. Ersteres könnte ins Straucheln geraten, wenn das Problem mehrere Schritte erfordert, während letzteres durch diese Schritte strategisch vorgeht. Mit RL lernt das Modell, jedes Token oder jede Aktion als Teil einer Trajektorie im Dienste eines Ziels zu betrachten. Durch sein Training lernt es, sich in Zustandsräumen zurechtzufinden, nicht nur lokale Korrelationen herzustellen. Dieser grundlegende Wandel – vom Erlernen statischer Eingabe-Ausgabe-Mappings zum Erlernen dynamischer Richtlinien – untermauert den Erfolg von Reasoning AI.
Die Kombination von groß angelegtem SSL (für Allgemeinwissen) mit RL (für zielzentrierte Verfeinerung) führt zu KI-Systemen, die besser verallgemeinern und Denkfähigkeiten über Domänen hinweg übertragen. Ein Sprachmodell, das über RL gelehrt wird, um bei mathematischen Problemen "gründlich nachzudenken", schneidet auch bei rechtlichen, biologischen und wirtschaftlichen Tests viel besser ab. Sobald das Modell gelernt hat, Rechenleistung der Argumentation in einem Bereich zuzuweisen, nutzt es diese Fähigkeit an anderer Stelle. Es öffnet sich eine neue Skalierungskurve, die über die Modellgröße oder die Datensatzgröße hinausgeht. Wir können die Argumentationsleistung verbessern, indem wir mehr Denkaufgaben trainieren oder ausgefeiltere Zielsignale integrieren.
Trajektorienoptimierung vs. One-Shot-Vorhersage
Um den Kontrast zu verdeutlichen: Bei der generativen KI ging es hauptsächlich um Vorhersagen, während es bei der Argumentations-KI um Optimierung geht (sowohl beim Training als auch bei der Inferenz). Ein generatives KI-Modell wie GPT-3 generiert Text, indem es vorhersagt, welches Token aufgrund seines Trainings wahrscheinlich als nächstes kommen wird. Es hat keinen Zweck, außer die Textverteilung nachzuahmen, die es gesehen hat. Es minimiert den Verlust einer Vorhersage des nächsten Tokens. Im Gegensatz dazu könnte ein Reasoning-KI-Modell explizit trainiert werden, um eine Belohnung wie "Problem richtig gelöst" zu maximieren, die davon abhängt, dass eine ganze Sequenz von Token kohärent und korrekt ist. Dies ist ein nicht differenzierbares, spärliches Ziel, das nicht durch standardmäßiges überwachtes Lernen optimiert werden kann. RL ist erforderlich.Das Modell lernt, den Raum der möglichen Ergebnisse nach solchen zu durchsuchen, die eine hohe Belohnung erzielen.
Dies führt zu grundlegend anderem Verhalten. Ein statischer Prädiktor entscheidet sich oft für eine plausible Antwort, die lokal richtig aussieht, auch wenn sie global falsch ist. Ein Bahnoptimierungsagent hat den Anstoß, jeden Schritt zu verifizieren und zu validieren, da ein einziger falscher Schritt die Belohnung zunichte machen kann. Es zeichnet sich durch Persistenz und Anpassungsfähigkeit aus. Bei der mathematischen Problemlösung kann ein traditionelles LLM eine schnelle Antwort geben, die ungefähr in der richtigen Größenordnung zu sein scheint, während ein RL-trainiertes Denkmodell eher die Arbeit anzeigt, bemerkt, ob Zwischenergebnisse falsch sind, und es erneut versucht, bis es die genau richtige Antwort erhält. Es behandelt die Aufgabe als ein Mini-Optimierungsproblem: Finden Sie eine Abfolge von Argumentationsschritten, die zur richtigen endgültigen Antwort führen. Dabei führt es eine effektive Suche – geleitet von den im Training erlernten Erkenntnissen – durch den Raum möglicher Lösungen durch.
Diese Ausrichtung auf "Erledige die Aufgabe" statt "das nächste Wort vorherzusagen" mache Reasoning AI für komplexe Aufgaben leistungsstark. Sie verlangt aber von uns, dass wir die Aufgabenstellung und ihre Erfolgskriterien klar definieren. Im Sinne des Reinforcement Learning brauchen wir eine gute Belohnungsfunktion. Wenn Sie angeben können, was den Erfolg einer komplexen Aufgabe ausmacht, kann eine KI zunehmend lernen, dies zu erreichen, wenn genügend Training und Inferenzberechnung vorhanden sind. Geben Sie dem Modell die richtigen Schnittstellen/Tools und entwerfen Sie ein angemessenes Belohnungssignal, und die KI kann den Rest durch Versuch und Irrtum herausfinden. Dies sind keine trivialen Probleme, aber sie sind wahrscheinlich für viele wertvolle Aufgaben lösbar. Dieses Framing erweist sich als nützlich, wenn Sie die Anwendung von Reasoning AI auf reale Domänen in Betracht ziehen, wie wir im Kontext von Unternehmensworkflows untersuchen werden.
Empirische Durchbrüche: Argumentation für KI-Benchmark-Leistung
Die Fähigkeiten der KI sind in den neuesten Frontier-Modellen am deutlichsten. Nehmen Sie das kürzlich veröffentlichte GPT-5.
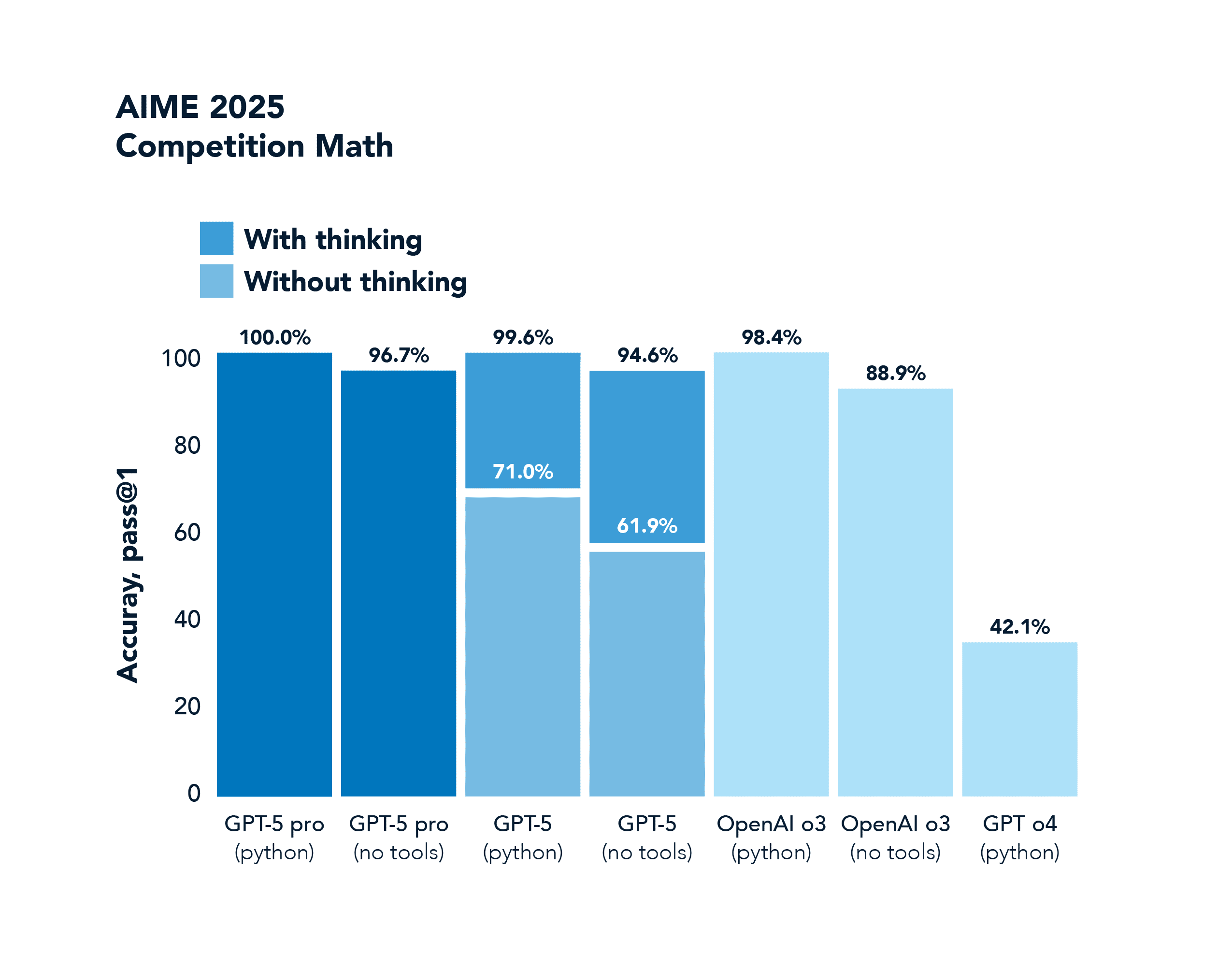
AIME ist ein mathematischer Benchmark für Wettbewerbe. GPT-4o erreicht 42,1 % und GPT-5 erfüllt diesen Benchmark mit 100,0 % vollständig Punktzahl.
SWE-Bench ist ein realer Codierungs-Benchmark. GPT-4o erreicht 30,8 %, während GPT-5 mit Denken 74,9 % erreicht.
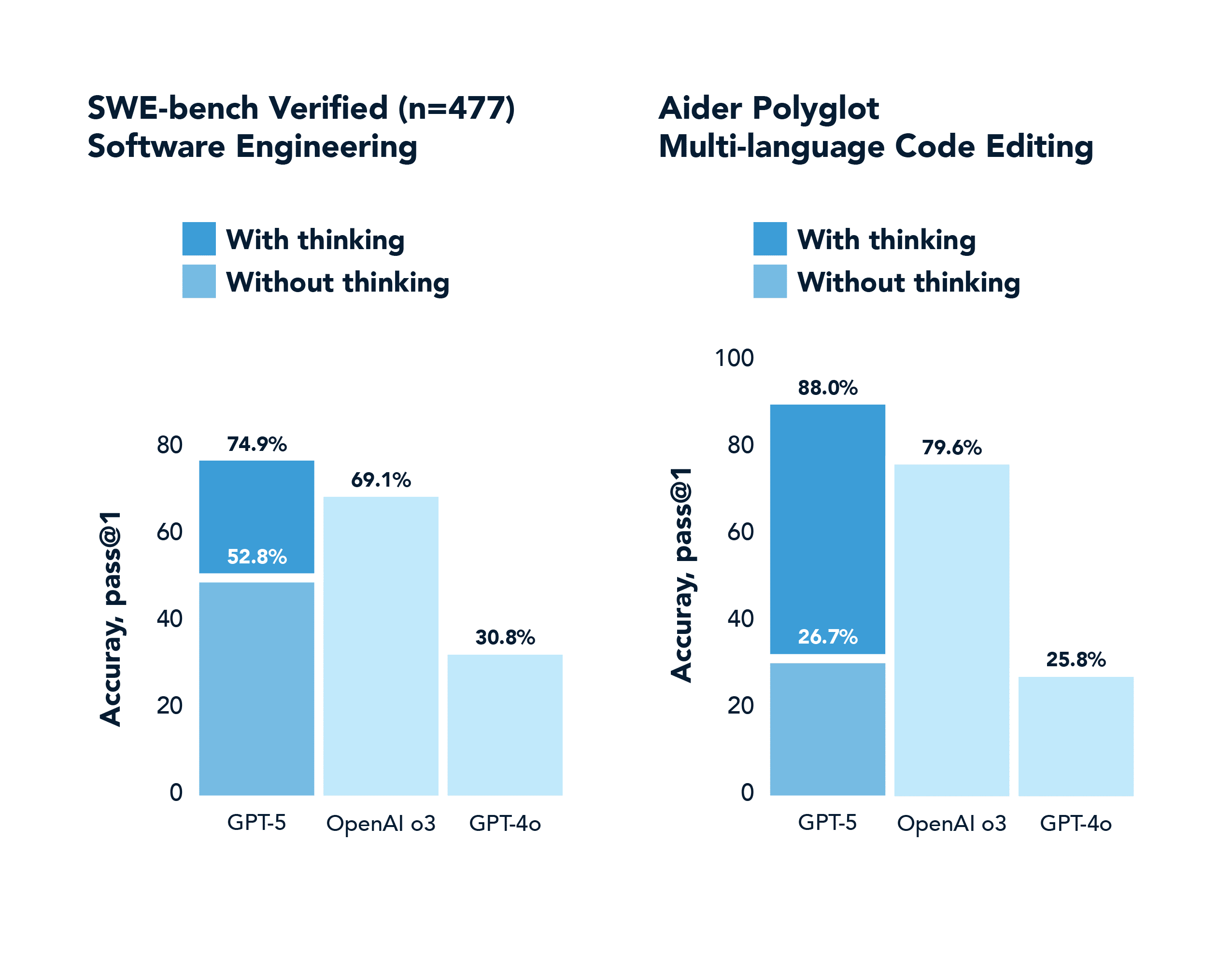
Die y-Achse in diesen Diagrammen ist erwähnenswert, da sie ein allgemeineres Phänomen widerspiegelt, das als pass@k Performance Shifts bekannt ist. Bei generativen Modellen, die schwierige Aufgaben ausführen, gab es traditionell eine große Lücke zwischen pass@1 (Erzeugung einer richtigen Lösung beim ersten Versuch) und pass@100 (Erzeugung von mindestens einer richtigen Lösung bei 100 Versuchen). Argumentationsmodelle haben diese Lücke drastisch geschlossen, indem sie bessere Problemlösungsstrategien verinnerlicht haben. Sie gelingt beim ersten Versuch viel häufiger, dank Chain-of-Thought und RL-Training. Und wenn sie mehrere Versuche bekommen, nutzen sie sie intelligent.
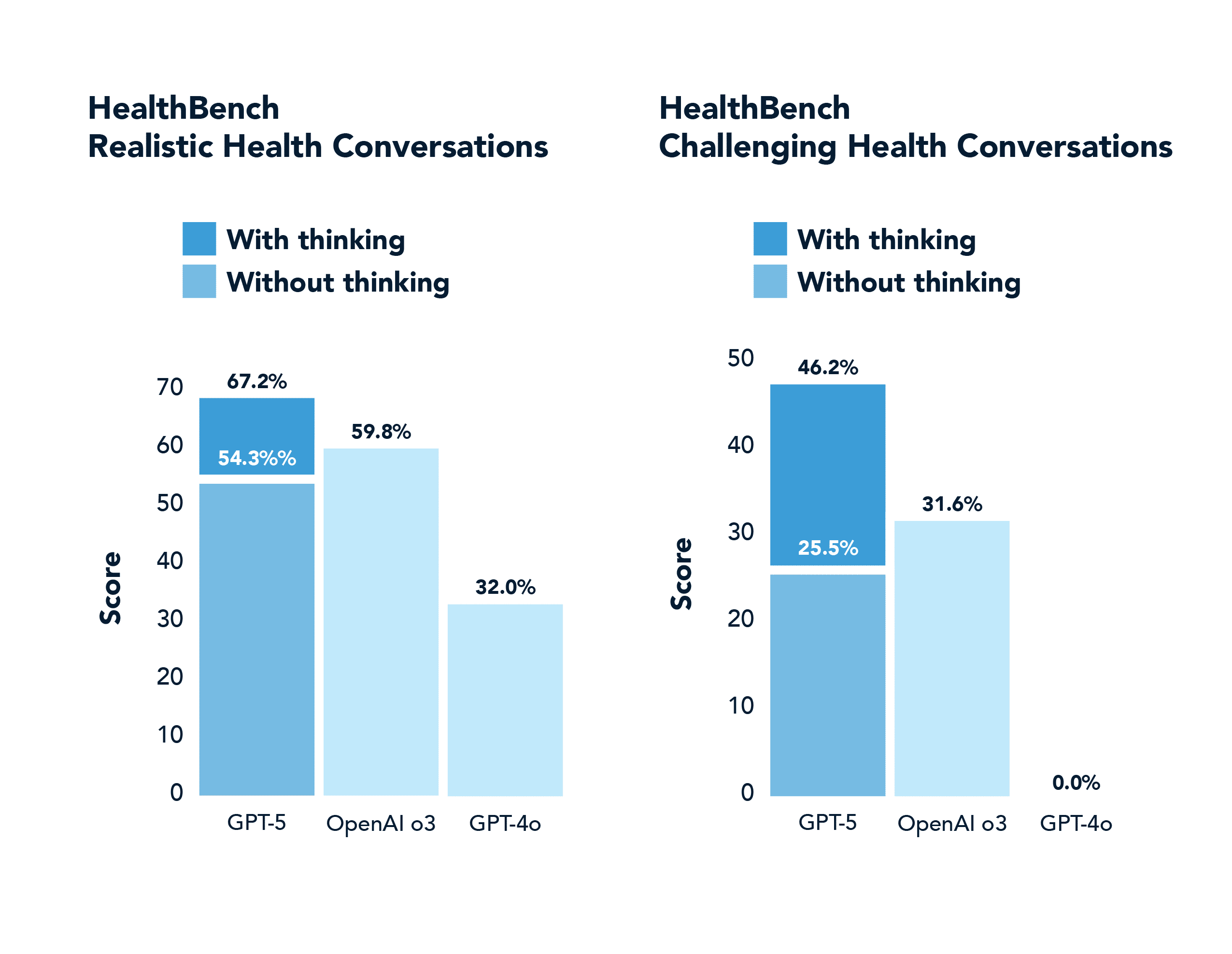
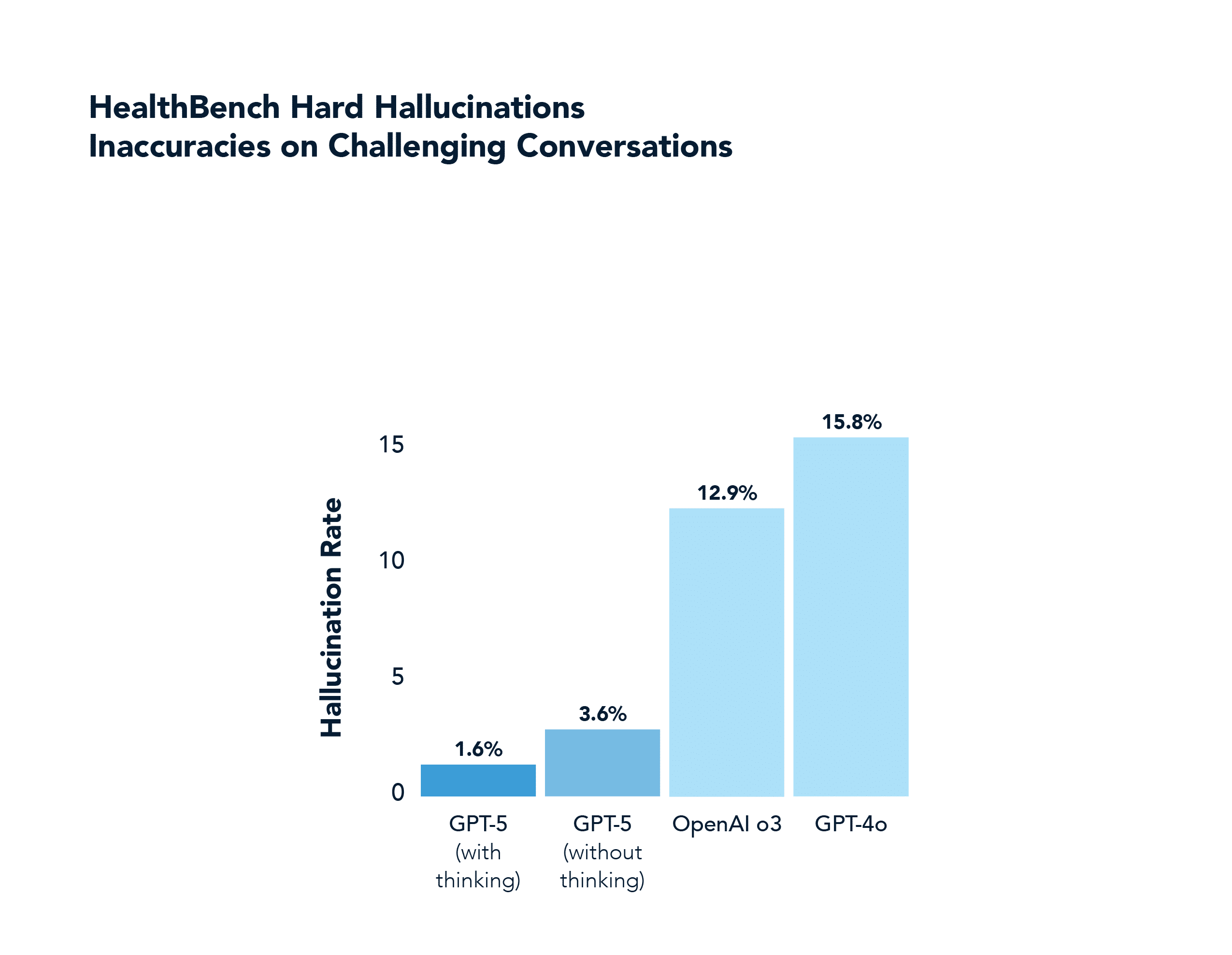
In einem Bereich, der nicht mit Mathematik oder Codierung zu tun hat, wie z. B. der Gesundheit, übertrifft GPT-5 GPT-4o ebenfalls deutlich, einschließlich der richtigen Beantwortung von fast der Hälfte der "schweren" Aufgaben, die 4o in 0,0 % der Fälle richtig beantwortete (und mit weit weniger Halluzinationen). Diese Domäne wurde im GPT-5-Launch-Stream hervorgehoben.
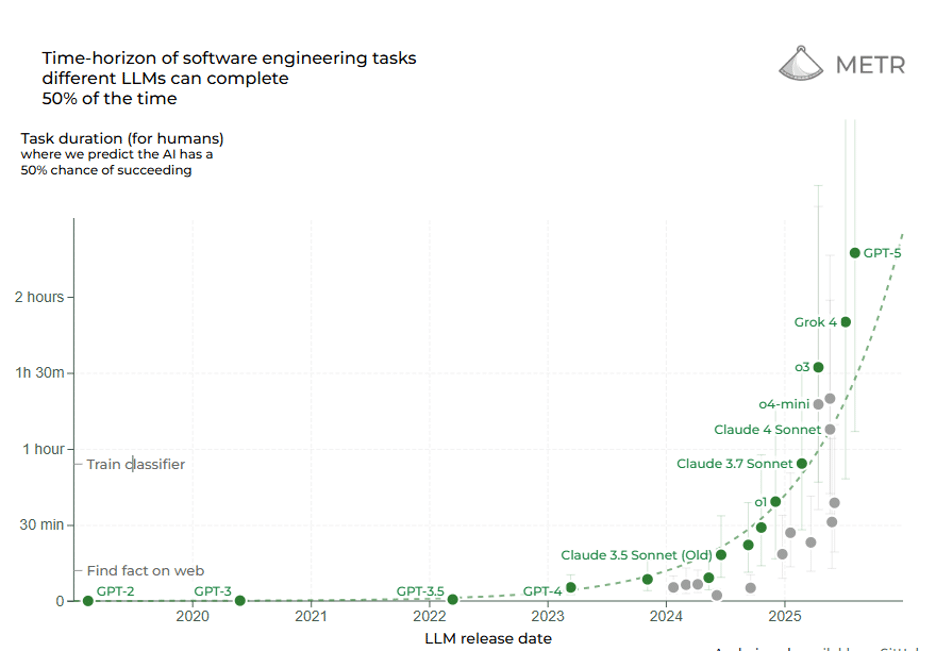
Eine andere Möglichkeit, die Grenzen der Reasoning-KI zu messen, ist der Zeithorizont: Wie lange eine Aufgabe (gemessen in menschlicher Zeit bis zur Erledigung) eine KI autonom bewältigen kann. Eine kürzlich durchgeführte Studie mit dem Namen Measuring Task Horizon (METR) ergab, dass seit 2019 die Dauer der Aufgaben, die KI-Systeme zuverlässig ausführen können, exponentiell zugenommen hat, mit einer Verdopplungszeit von etwa 7 Monaten. Im Jahr 2019 könnte die beste KI Aufgaben bewältigen, die für einen Menschen nur wenige Sekunden dauern; Bis 2023 erledigten sie Aufgaben, die mehrere Minuten dauerten; Jetzt, im Jahr 2025, sehen wir, dass Aufgaben in der Größenordnung von Stunden von KI erledigt werden. Benchmarks, die das Schreiben von Code oder das Betreiben von Recherchen beinhalten (mit denen Menschen Stunden verbringen), sind jetzt in Reichweite: Frontier-Reasoning-Modelle im Jahr 2025 erreichen einen Erfolg von 50 % bei Aufgaben, die eine Person mehr als 2 Stunden dauern würde. Laut METR könnte das ursprüngliche Denkmodell o1 von OpenAI (veröffentlicht im Dezember 2024) eine 39-minütige Aufgabe in 55,9 % der Fälle erledigen; das kürzlich veröffentlichte GPT-5 kann eine 2 Stunden und 17 Minuten lange Aufgabe in 69,6 % der Fälle (!) erledigen. Die Trendlinie deutet darauf hin, dass sich der Zeithorizont der KI in den nächsten 5 Jahren auf Tage oder Wochen erweitern könnte, was bedeutet, dass eine KI möglicherweise ein Projekt durchführen könnte, das sich über viele Arbeitstage erstreckt. Reasoning AI erweitert nicht nur die Genauigkeit, sondern auch den Umfang der Autonomie.
Die Beweise deuten überwältigend darauf hin, dass wir uns in einem neuen Regime der KI-Fähigkeiten befinden. Die vorherige Generation von Modellen folgte glatten Skalierungskurven – vorhersehbare Verbesserungen mit mehr Parametern oder Daten, aber innerhalb desselben Betriebsmodus. Die neue Generation – Reasoning AI-Agenten mit RL und Testzeitsuche – führt zu Diskontinuitäten in diesen Kurven. Sie erreichen bei bestimmten Aufgaben ein Leistungsniveau, das mit dem alten Ansatz unmöglich war.
Reasoning AI stellt neue komplexe Aufgaben in den Fokus
Der spannendste Aspekt von Reasoning AI ist die Bandbreite an realen Aufgaben, die bisher für Maschinen viel zu komplex und nuanciert waren. Unternehmensprozesse beinhalten oft langwierige Abfolgen von Entscheidungen, viele unstrukturierte Informationen und die Notwendigkeit einer Fehlerüberwachung – genau hier setzt Reasoning AI an. In Sektoren wie Finanzen, Recht, Medizin und Ingenieurwesen gibt es viele solcher Beispiele: langwierige Steuervorbereitungen, die Erstellung von Rechtsverträgen, die Durchführung klinischer Analysen, die Fehlerbehebung bei technischen Entwürfen. Diese erfordern oft 2-10 Stunden menschliche kognitive Arbeit pro Instanz, mit erheblichem Hin und Her und Überprüfungen.
Bis vor kurzem scheiterten Versuche, diese mit KI zu automatisieren, weil herkömmliche Modelle unweigerlich irgendwann aus der Spur geraten würden und keine Möglichkeit mehr hätten, sich davon zu erholen. Aber mit dem Aufkommen zielorientierter, sich selbst korrigierender KI-Agenten rücken viele dieser "nicht automatisierbaren" Aufgaben in den Geltungsbereich.
Fallstudie: Automatisierung der Steuervorbereitung mit Reasoning AI
Betrachten Sie den Arbeitsablauf bei der Erstellung einer komplexen Steuererklärung für ein kleines Unternehmen oder eine Einzelperson mit mehreren Einkommensquellen und Abzügen (dieser spezielle Anwendungsfall wurde im Dwarkesh Podcast mit Sholto Douglas und Trenton Bricken von Anthropic besprochen). Diese Aufgabe kann leicht 4-6 Stunden der Zeit eines Buchhalters umfassen. Es beinhaltet das Sammeln zahlreicher Dokumente (W2s, 1099s, Quittungen), das Interpretieren von Steuerregeln und -codes, das Durchführen von Schritt-für-Schritt-Berechnungen für verschiedene Formulare, das Überprüfen dieser Formulare auf Konsistenz und das Iterieren, wenn Fehler gefunden werden oder neue Informationen ans Licht kommen. Die Steuervorschriften ändern sich jedes Jahr und haben viele Sonderfälle, die allgemeines Wissen und Anpassung erfordern. Es ist ein Paradebeispiel für einen Prozess mit hoher Komplexität und hohen Konsequenzen.
Im Zeitalter der analytischen KI hätte man vielleicht eine Software mit einem starren Flussdiagramm oder einer Reihe von Formeln entwickelt, um bei der Besteuerung zu helfen, aber sie würde nichts Unerwartetes bewältigen; Jede Abweichung erforderte menschliches Eingreifen. Im Zeitalter der generativen KI könnten Sie ein Sprachmodell verwenden, um bestimmte Steuerfragen zu beantworten oder ein einzelnes Formular aus Daten auszufüllen, aber es würde weder den gesamten Prozess mit mehreren Formularen zuverlässig verwalten, noch würde es wissen, wie es sich selbst überprüfen kann.
Hier kommt Reasoning AI ins Spiel. Ein Argumentationsagent für die Steuervorbereitung würde das Problem ähnlich wie ein menschlicher Steuerfachmann angehen, jedoch mit verbesserten Rechenkapazitäten:
Das Ziel und die Einschränkungen verstehen: Die KI erhält das Ziel (Erstellung einer vollständigen und genauen Steuererklärung für das Jahr X für den Kunden Y) und Zugriff auf Ressourcen: die Dokumente des Kunden (per OCR analysiert), Steuersoftware-APIs oder Formularvorlagen und eine Wissensdatenbank der Steuergesetze. Entscheidend ist, dass es ein Mittel zur Überprüfung der Richtigkeit erhält. Es kann eine offizielle IRS-Berechnungs-API abfragen oder eine bekanntermaßen gute Simulation verwenden, um zu überprüfen, ob die Rendite wahrscheinlich die Prüfprüfungen bestehen würde (im Wesentlichen ein Belohnungssignal für eine korrekte Rendite).
Planung und Zerlegung: Der Agent unterteilt die Aufgabe in Unteraufgaben: (1) Analysieren und Extrahieren aller Einkommensposten aus Dokumenten, (2) Bestimmen, welche Steuerformulare erforderlich sind, (3) Ausfüllen der erforderlichen Felder Schritt für Schritt für jedes Formular, (4) Überprüfen von Summen und Referenzen zwischen Formularen, (5) Überprüfen auf mögliche Optimierungen oder Fehler, (6) Erstellen der endgültigen Erklärung für die Einreichung.
Iteratives Befüllen und Prüfen: Für jede Teilaufgabe ruft die KI entsprechende Tools auf. Es könnte die Gedankenkette verwenden, um ein 1099-B-Formular zu interpretieren und relevante Zahlen zu extrahieren, indem Berechnungen für Kapitalgewinne durchgeführt werden. Es überträgt diese Zahlen in Anhang D und stellt dann sicher, dass das Ergebnis von Anhang D korrekt in das Hauptformular 1040 übertragen wird. Bei jedem Schritt kann es pausieren und prüfen: Entspricht die Anzahl auf Schedule D Zeile 7 der Summe von 1099-B? Ist dies nicht der Fall, wird ein Fehler erkannt und korrigiert. Hier erweist sich die Fehlerbeseitigung als entscheidend – ein Reasoning AI-Agent würde darauf trainiert, Formularsummen immer zu überprüfen und zu iterieren, bis sie übereinstimmen. Im Gegensatz zu einem generativen Modell, das inkonsistente Zahlen ausgeben kann, hat ein Reasoning Agent eine interne Schleife: Wenn Prüfungen fehlschlagen, korrigieren und wiederholen.
Generalisierung und Adaption: Angenommen, der Kunde hat eine ungewöhnliche Steuersituation (Kryptowährungseinkommen oder einen obskuren Abzug). Ein Standardprogramm kann abstürzen oder ein Basismodell halluzinieren. Aber unsere Reasoning-KI, die mit Abruffunktionen ausgestattet ist, kann die relevante Steuergesetzgebung oder den Präzedenzfall dynamisch abrufen und in ihre Gedankenkette einbeziehen. Da es nach Prinzipien (Zielzufriedenheit) und nicht nur nach Mimikry arbeitet, kann es mit neuartigen Szenarien geschickter umgehen. Es wird festgelegt, wie mit neuen Eingaben umgegangen werden soll, um die Genauigkeit und Compliance zu maximieren.
Argumentation und Zuweisung von Unterzielen: Der Agent legt interne Unterziele fest, z. B. "Gesamteinkommen berechnen", "Gesamtabzüge berechnen", "geschuldete Steuern berechnen", von denen jedes korrekt sein muss, damit die Gesamtrendite korrekt ist. Wenn die abschließende Überprüfung fehlschlägt, kann festgestellt werden, bei welchem Teilziel wahrscheinlich ein Fehler aufgetreten ist, und dieser spezifisch erneut überprüft werden. Dieses gezielte Backtracking ist nur möglich, weil die KI nicht die gesamte Rendite auf einmal generiert. Es ist eine Argumentation durch einen strukturierten Prozess.
Abschließende Überprüfung: Erst wenn alle Validierungstests bestanden sind, stoppt die KI und übermittelt die Rückgabe: Die Rückgabe ist in sich konsistent und besteht vielleicht sogar einen Simulationstest. Dies liefert ein robustes Belohnungssignal: Belohnung = 1, wenn die Rückgabe gültig und konsistent ist, sonst 0. Zur Laufzeit verwendet der Agent diese Checklisten, um sicherzustellen, dass er die Erfolgskriterien erfüllt.
Die Steuervorbereitung kann als langfristiges Denkproblem mit überprüfbaren Teilzielen betrachtet werden, was es für Reasoning AI zugänglich macht. Wir brauchten die Kombination von Komponenten, die es jetzt gibt: OCR und Informationsextraktion, ein vortrainiertes Wissensmodell, ein RL-Richtlinien-Overlay und eine Testzeitsuche.
Eine solche KI würde den Zeit- und Kostenaufwand für die Steuervorbereitung drastisch reduzieren. Es könnte unermüdlich arbeiten und in wenigen Minuten bewältigen, was Experten Stunden in Anspruch nimmt, indem es bei Bedarf Brute-Force-Berechnungen einsetzt. Und vor allem würde es nicht so leicht kaputt gehen oder aufgeben – wenn eine Zahl nicht aufgeht, bemerkt sie es und repariert sie. Das stellt eine grundlegende Veränderung im Vergleich zu früherer Software dar.
Reasoning AI in schwer zu verifizierenden Bereichen: Weitere Fallstudien
Einige Arbeitsabläufe sind schwierig, nicht weil die Argumentationskette lang ist (wie bei Steuern), sondern weil die Grundwahrheit selbst mehrdeutig, unvollständig oder umstritten ist. Klassische Beispiele sind die Compliance-Überwachung, die Auslegung von Rechtsvorschriften, die Forschungssynthese und die strategische Planung. Die Fehlermodi sind hier subtiler: Die Ausgabe mag plausibel aussehen, aber versteckte Widersprüche oder übersehene Einschränkungen enthalten.
RL-Forscher haben damit begonnen, Verifizierungsmodule in die Belohnungsfunktion selbst einzubetten. In Trust, But Verify, Liu et. al trainieren Sprachmodelle, um Antworten vorzuschlagen und dann ihre eigene Gedankenkette zu kritisieren; Eine Belohnung wird nur gewährt, wenn sich der Kritiker und ein externer Prüfer einig sind. Bei offenen Policy-Fragen, bei denen es kein einheitliches Label gibt, reduzierte der Selbstverifizierungsagent halluzinatorische Fehler um 38 % im Vergleich zu RLHF-Ausgangswerten (Reinforcement Learning from Human Feedback).
Diese Ergebnisse deuten auf einen Weg in die Zukunft hin: Entwerfen Sie für jede schwer zu überprüfende Aufgabe Teilprüfungen, die unbestreitbar sind (z. B. logische Konsistenz, gesetzliche Zitiergenauigkeit, numerische Ausgewogenheit). Reinforcement Learning lehrt das Modell dann, seine Argumentation durch diese Kontrollpunkte zu leiten. Im Laufe der Zeit verinnerlicht der Agent Heuristiken, um zu erkennen , wann er auf wackeligen Beinen steht, und löst zusätzliche Beweiserhebungenaus – ähnlich wie ein erfahrener Prüfer nach einem Beleg fragt, wenn sich etwas "nicht in Ordnung anfühlt". Schwer zu verifizierende Arbeit wird daher leichter zu handhaben, wenn die KI jeden Schritt lokal nachweisen kann, selbst wenn das globale Ergebnis subjektiv ist.
Die Steuervorbereitung ist nur ein Beispiel. Ähnliche Analysen gelten für viele andere komplexe Aufgaben:
Finanzprüfung: Das Durchgehen von Tausenden von Transaktionen, um Diskrepanzen zu finden, erfordert eine Argumentation über jede einzelne und die Aggregation von Beweisen. Eine Reasoning-KI könnte eine Prüfung planen, sie durch die Untersuchung von Aufzeichnungen durchführen, Anomalien kennzeichnen und ihre Strategie anpassen, wenn unerwartete Muster auftauchen – und so letztendlich sicherstellen, dass die Bücher übereinstimmen.
Überprüfung des rechtlichen Vertrags: Um komplexe Verträge zu verstehen, sie mit Unternehmensstandards zu vergleichen und Überarbeitungen vorzuschlagen, bedarf es sorgfältiger Lektüre, logischer Argumentation über Klauseln und kreativer Vorschläge. Ein Argumentationsmodell könnte jede Klausel nacheinander untersuchen, auf eine Wissensdatenbank mit riskanten Phrasen verweisen und einen Vertragsentwurf iterativ verfeinern.
Medizinische Diagnose und Behandlungsplanung: Anhand der Vorgeschichte und der Symptome eines Patienten könnte ein Argumentationsagent mögliche Diagnosen erstellen, mehr Informationen sammeln, dann eingrenzen und eine Behandlung vorschlagen. Dieser natürlich iterative Argumentationsprozess könnte mit RL auf der Grundlage von Ergebnissen und einer mehrstufigen Interaktionsplanung verbessert werden.
Fehlerbehebung beim Kundensupport: Eine KI, die komplizierte technische Probleme beheben kann, indem sie systematisch Informationen sammelt, Hypothesen aufstellt, Lösungen testet und nachverfolgt, kann Überraschungen bewältigen, die skriptgesteuerte Abläufe nicht bewältigen können. Geschult auf das Ziel, Probleme mit hoher Kundenzufriedenheit zu lösen, sollte es hartnäckig und gründlich sein.
VomLLM-Wrapper zum "RL Sculptor": Das Anpassen der Argumentation schafft echte Wettbewerbsvorteile
Es gibt auch eine strategische Implikation. Unternehmen, die wertvolle komplexe Aufgaben identifizieren und maßgeschneiderte Reasoning-KI-Lösungen entwickeln, können erhebliche Wettbewerbsvorteile erzielen. Der Erfolg hängt oft davon ab, die richtigen Belohnungsdefinitionen und kuratierten Trainingsschleifen zu haben und eine hohe Inferenzberechnung zu tolerieren. Wir haben die Tage der LLM-Wrapper hinter uns. Sie können nicht einfach Standard-APIs verwenden. Du musst sie bauen, möglicherweise Daten sammeln oder Simulatoren sammeln, um darauf zu trainieren. Wenn ein Buchhaltungssoftware-Unternehmen eine proprietäre RL-Umgebung für Steuererklärungen erstellt und eine spezialisierte Reasoning-KI darauf trainiert, ist das eine erhebliche Investition, die nicht leicht repliziert werden kann. Das Endergebnis wäre eine KI, die nicht nur Steuern automatisiert, sondern sich kontinuierlich verbessert. Eine solche KI könnte als Premium-Inferenz-lastiger Service angeboten werden, bei dem Steuern über Nacht von einer Cloud-KI mit 100× mehr Rechenleistung pro Aufgabe als bei typischen Modellen durchgeführt werden, um sicherzustellen, dass jeder Abzug optimiert und jede Zahl doppelt überprüft wird. Die Kosten pro Abfrage können höher sein (der ARC-Highscore von o3 high kostet 200 USD+ pro Aufgabe in der Rechenleistung), aber der gelieferte Wert könnte dies rechtfertigen. Bei vielen Unternehmensaufgaben mit hohem Einsatz sind Genauigkeit und Gründlichkeit weit mehr wert als Rechenzyklen. Diese Unternehmen werden zu Beginn mehr Kapital benötigen, aber sie werden Leistungssprünge schaffen, die für Unternehmen in der GenAI-Ära ungewöhnlich sind.
OpenAI bietet "hocheffiziente" und "niedrige" Modi, wobei letzterer viel mehr Rechenleistung verbraucht, um höhere Erfolgsquoten zu erzielen. Sie haben Preismodelle eingeführt, um dies zu berücksichtigen. Ein Unternehmen, das Reasoning AI einsetzt, könnte in ähnlicher Weise Servicestufen anbieten: einen schnellen Modus, der normalerweise funktioniert, und einen "gründlichen Modus", in dem der KI zusätzliche Zeit/Rechenleistung zur Verfügung steht, um den Erfolg zu maximieren. Diese zusätzlichen Zyklen können damit verbracht werden, tiefer zu argumentieren oder mehr Möglichkeiten zu erkunden. In jedem Fall kann es ein Verkaufsargument sein: "Unsere KI wird es richtig machen, auch wenn sie länger nachdenken muss – und wir haben validiert, was 'richtig' für Ihr Unternehmen bedeutet."
Dies deutet darauf hin, dass Early Mover beim Einsatz von Reasoning AI für komplexe Workflows starke Vorteile erzielen werden. Sie sammeln aufgabenspezifische Daten und Feedback (da jede Bereitstellung Protokolle darüber liefert, wie die KI argumentiert hat und wo sie Probleme hatte, was das System verfeinern kann); ihre Belohnungsmetriken im Laufe der Zeit zu verbessern (zu bemerken, wenn die Belohnung etwas verfehlt, und sie anzupassen); und entwickeln Sie Integrationskompetenz – mit dem Wissen, wie der KI-Agent effizient mit vorhandener Software oder Human-in-the-Loop-Setups interagieren kann. Nachzügler müssen einen steileren Hügel erklimmen.
Fazit: Argumentations-KI erfordert einen Mindset-Shift
In der Entwicklung der KI erleben wir einen Wandel, der so grundlegend ist wie die Einführung von Deep Learning selbst. Reasoning AI läutet ein Paradigma ein, in dem KI-Systeme keine statischen Prädiktoren sind, sondern aktive Problemlöser, die planen, experimentieren und sich selbst korrigieren können, um Ziele zu erreichen. Dieses neue Paradigma wird durch die Kombination der Stärken selbstüberwachter Grundlagenmodelle (umfangreiches Wissen und Mustererkennung) mit Reinforcement Learning (Zieloptimierung und Feedback) und der Einbeziehung umfangreicher Inferenz-Zeit-Berechnungen (iteratives Denken) ermöglicht. Das Ergebnis ist eine KI, die bei komplexen Aufgaben weitaus verallgemeinerbarer und zuverlässiger ist als ihre Vorgänger.
Während die analytische KI mit klar definierten Eingaben zu tun hatte und die generative KI den flüssigen Ausdruck beherrschte, bewältigt die Reasoning AI die chaotischen, langwierigen Herausforderungen der realen Welt. Es nähert sich der Kompetenz auf menschlichem Niveau in Bereichen, die "fluide Intelligenz" erfordern – die Effizienz und Anpassungsfähigkeit des Kompetenzerwerbs, die François Chollet bei der Definition von Intelligenz hervorhob. Der Beweis dafür sind die Leistungssprünge auf breiter Front, wobei Modelle wie o3 einen "echten Durchbruch" über frühere Einschränkungen markieren und GPT-5 Hörfragen zur Gesundheit löst, die nicht logische Modelle wie 4o in 0,0 % der Fälle lösen.
Doch das ist wahrscheinlich erst der Anfang. Wenn diese Techniken ausgereift sind, werden wir sehen, dass Reasoning KIs die Werkzeugnutzung verbessern und Langzeitgedächtnissysteme nutzen, um Wissen über Sitzungen hinweg zu behalten. Mit jeder Erweiterung wird die Reichweite weiter ausgebaut. Die genannten Herausforderungen – den Modellen die richtige Genauigkeit der Weltinteraktion und die richtigen Erfolgsmetriken zu verleihen – werden aktiv angegangen. Bei Robotern wenden Forscher die gleichen Denkarchitekturen an, damit sie physische Aktionen planen können. In der Software werden Agenten so gebaut, dass sie Computer verwenden, um Aufgaben zu erledigen und die Welt selbst in die "Umgebung" für ihr RL-Training zu verwandeln. Schon bald könnte es normal sein, KI-Kollegen zu haben, die mehrtägige Projekte übernehmen, sich mit Menschen abstimmen und autonom auf Ziele zusteuern, dabei lernen und sich anpassen. Menschliche Arbeit, die einen langen Schwanz neuartiger, nicht mehr trainierter Verteilungsaufgaben aufweist, die in der Vergangenheit menschliches Denken erforderten, ist jetzt mit Reasoning AI zugänglich.
Für Unternehmen und die Gesellschaft stellt das Aufkommen einer argumentationsfähigen KI sowohl Chancen als auch Verantwortung dar. Die Chance liegt darin, eine immense Produktivität zu erschließen und Probleme anzugehen, die zuvor zu komplex oder kostspielig waren, um sie zu lösen. Harte wissenschaftliche Forschung, massive Optimierungen des technischen Designs und personalisierte Bildungspläne könnten alle durch KIs beschleunigt werden, die viel schneller als wir über Daten und Möglichkeiten nachdenken und sich gleichzeitig selbst korrigieren, um auf Kurs zu bleiben. Die Verantwortung ergibt sich aus der Tatsache, dass eine stärkere Argumentation auch eine stärkere Fehlschlussfolgerung bedeutet, wenn Ziele falsch spezifiziert werden. Wir müssen sicherstellen, dass die Belohnungssignale, die wir geben, mit den Ergebnissen übereinstimmen, die wir uns wünschen – sonst könnte ein Super-Reasoner clevere Wege finden, das System auszutricksen (das klassische "Belohnungs-Hacking"-Problem). Die ermutigende Nachricht ist, dass die gleichen Werkzeuge, die KI zu besseren Denkern machen, sie auch zu transparenteren Denkern machen können. Indem wir sie Gedankenketten externalisieren lassen, erhalten wir einen Einblick in ihren Entscheidungsprozess, der bei Audits und Abstimmungen hilfreich sein kann. Wir haben Hinweise darauf gesehen, dass die Integration von Ethik- oder Sicherheitsaspekten in die Gedankenkette zu Modellen führen kann, die sowohl intelligenter als auch sicherer sind.
Zusammenfassend lässt sich sagen, dass wir den Anbruch der Ära der logischen KI erleben. Es stellt eine neue Fähigkeitsgrenze dar, bei der Maschinen nicht nur Antworten generieren, sondern auch aktiv Dinge herausfinden. Dieser Paradigmenwechsel wird die Grenze der Aufgaben, die wir als automatisierbar betrachten, neu definieren. In den kommenden Jahren wird es darum gehen, diese Feedbackschleifen zu erweitern, sie auf mehr Aufgaben auszuweiten und diese Argumentationsagenten in die Struktur unserer Arbeitsweise und Problemlösung zu integrieren. Diejenigen, die diesen Wandel verstehen und annehmen – indem sie in die notwendigen Daten, das Belohnungsdesign und die Rechenleistung investieren – werden an der Spitze der nächsten Innovationswelle stehen. Vielleicht nähern wir uns tatsächlich den Grenzen traditioneller Skalierungsansätze, aber wir erklimmen jetzt eine neue Kurve, die von KI angetrieben wird, die zu denken lernt. Die Reise auf dieser Kurve hat gerade erst begonnen und verspricht, das, was wir uns unter KI vorstellen, zu verändern.
Die hier enthaltenen Informationen basieren ausschließlich auf den Meinungen von Brandon Gleklen und nichts sollte als Anlageberatung ausgelegt werden. Dieses Material wird zu Informationszwecken zur Verfügung gestellt und ist und darf in keiner Weise als Rechts-, Steuer- oder Anlageberatung oder als Angebot zum Verkauf oder als Aufforderung zur Abgabe eines Angebots zum Kauf einer Beteiligung an einem Fonds oder Anlagevehikel angesehen werden, das von Battery Ventures oder einer anderen Battery verwaltet wird. Die hier geäußerten Ansichten sind ausschließlich die der Autoren.
Die obigen Informationen können Prognosen oder andere zukunftsgerichtete Aussagen zu zukünftigen Ereignissen oder Erwartungen enthalten. Vorhersagen, Meinungen und andere Informationen, die in dieser Veröffentlichung diskutiert werden, können sich ständig und ohne Vorankündigung ändern und sind nach dem angegebenen Datum möglicherweise nicht mehr zutreffend. Battery Ventures übernimmt keine Verpflichtung und verpflichtet sich nicht, zukunftsgerichtete Aussagen zu aktualisieren.
*Bezeichnet ein Battery -Portfolio-Unternehmen. Für eine vollständige Liste aller Battery und -ausgänge klicken Sie bitte hier.

Ein monatlicher Newsletter zum Austausch neuer Ideen, Erkenntnisse und Einführungen, um Unternehmer*innen beim Ausbau ihres Geschäfts zu helfen.